Apache Spark / Dataframe API vs. SQL
Pracovat s daty pomocí Apache Spark je možné hned několika způsoby. Pokud pocházíte spíše z prostředí softwarového vývoje, budete zřejmě inklinovat k použití Dataframe API, tzn. k volání funkcí select, filter, orderBy a dalších.
df.select(
col("hodnota").as("quantity"),
col("rok").as("year"),
col("DRUHZVIRE_txt").as("animal")
).filter(col("uzemi_txt") === lit("Olomoucký kraj"))
.filter(col("year") === lit("2018"))
.orderBy(desc("quantity"))
.show()
+--------+----+---------------+ |quantity|year| animal| +--------+----+---------------+ | 609373|2018| Drůbež| | 146772|2018| Slepice| | 92806|2018| Skot| | 85838|2018| Prasata| | 39619|2018| Krávy| | 9936|2018| Ovce| | 5589|2018|Prasnice chovné| | 1829|2018| Koně| | 1599|2018| Kozy| +--------+----+---------------+
Pro ty, kterým se na druhou stranu lépe přemýšlí ve „standardním“ SQL, je určen Spark SQL modul.
df.createOrReplaceTempView("animals")
sparkSession
.sql(
"""SELECT hodnota AS quantity
| , rok AS year
| , DRUHZVIRE_txt AS animal
| FROM animals
| WHERE (uzemi_txt='Olomoucký kraj')
| AND (rok='2018')
| ORDER BY 1 DESC
|""".stripMargin
)
.show()
+--------+----+---------------+ |quantity|year| animal| +--------+----+---------------+ | 609373|2018| Drůbež| | 146772|2018| Slepice| | 92806|2018| Skot| | 85838|2018| Prasata| | 39619|2018| Krávy| | 9936|2018| Ovce| | 5589|2018|Prasnice chovné| | 1829|2018| Koně| | 1599|2018| Kozy| +--------+----+---------------+
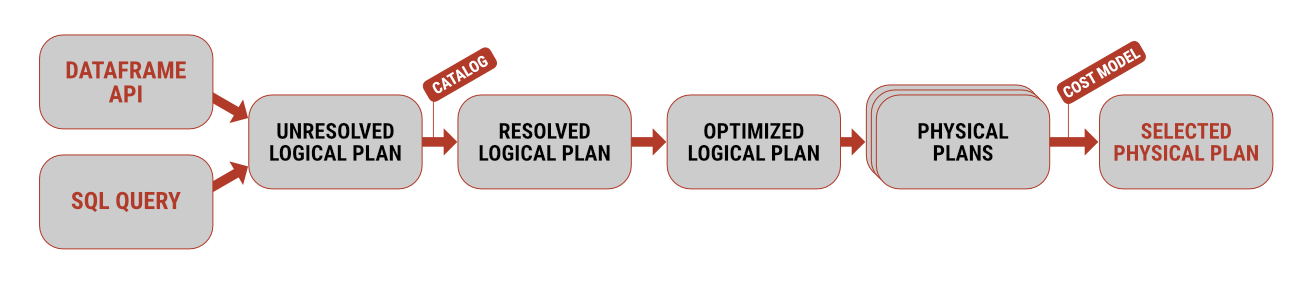
Oba přístupy mají své pro a proti, z hlediska výkonnosti jsou ale identické. Na pozadí se u obou dotazů nejdříve vygeneruje tzv. prázdný plán, který zaručuje formální správnost zápisu. Ten je dále podroben věcné analýze, tedy ověření, že použité tabulky a sloupce opravdu existují a že se použité datové typy shodují se zdrojovými daty. Teprve po tomto kroku vstupuje do hry jedna z nejsilnějších stránek Sparku – optimalizace, vytvoření několika fyzických plánů (= způsobů, jak příkazy provést na konkrétním železe) a následně volba toho, který dokáže dotaz zpracovat za co nejkratší čas a s co možná nejmenším množstvím prostředků.
Celý projekt s příklady je k dispozici na githubu.