Apache Spark / Dataframe API vs. SQL
Pracovat s daty pomocí Apache Spark je možné hned několika způsoby. Pokud pocházíte spíše z prostředí softwarového vývoje, budete zřejmě inklinovat k použití Dataframe API
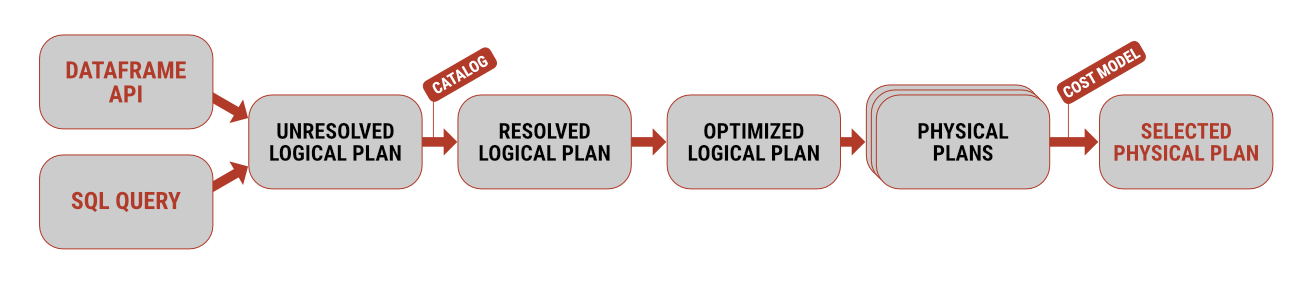
Pracovat s daty pomocí Apache Spark je možné hned několika způsoby. Pokud pocházíte spíše z prostředí softwarového vývoje, budete zřejmě inklinovat k použití Dataframe API
Omezení seřazených dat podle počtu řádků se ve starších verzích muselo realizovat vnořeným dotazem. Ten tabulku nejprve uspořádal a až poté bylo možné odfiltrovat počet.
Možnost definovat PL/SQL funkci nebo proceduru uvnitř SQL dotazu může na první pohled vypadat zvláštně, má to ale jednu podstatnou výhodu – databáze nemusí přepínat kontext, což vede v určitých případech k masivnímu nárůstu výkonu.
Poslední komentáře
-

Pavel
Hodně užitečná věc. Vyžaduje ale, aby i klient…
Přidat komentář...