Apache Spark / Proceduralní SQL
Apache Spark 4.0 přináší významné rozšíření možností jazyka SQL v podobě experimentální podpory procedurálního programování.
Množství dat každým rokem exponenciálně roste, na což nejsou tradiční relační databáze připraveny. Zkracuje se interval mezi zpracováním, analyzují se data v nestrukturované podobě z mnoha zdrojů. Tuto problematiku řeší technologie okolo platformy Hadoop jako například distribuovaný souborový systém HDFS, výpočetní framework Apache Spark nebo sloupcové formáty pro ukládání dat typu Apache Parquet a další.
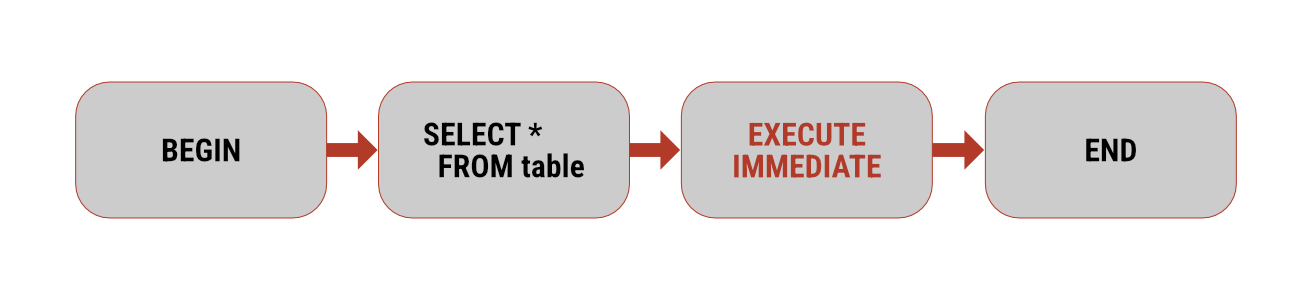
Apache Spark 4.0 přináší významné rozšíření možností jazyka SQL v podobě experimentální podpory procedurálního programování.
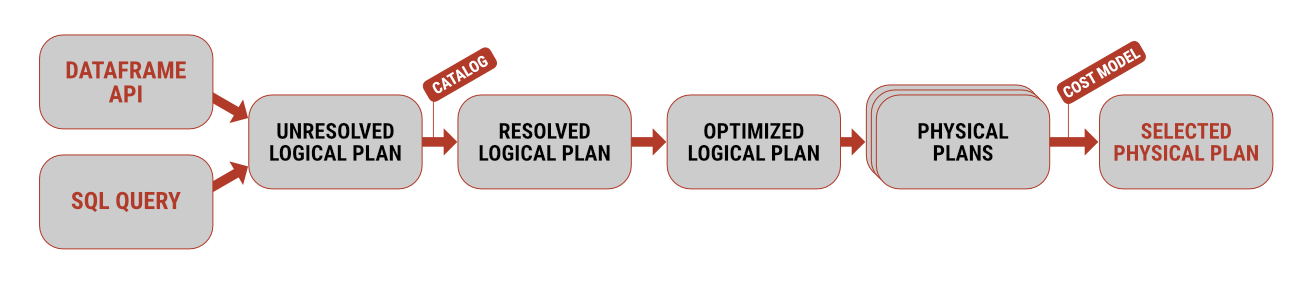
Pracovat s daty pomocí Apache Spark je možné hned několika způsoby. Pokud pocházíte spíše z prostředí softwarového vývoje, budete zřejmě inklinovat k použití Dataframe API

Apache Spark, jakožto jeden z hlavních zástupců distribuovaných výpočetních systémů, podporuje hned několik formátů pro čtení a zápis dat. Tím pravděpodobně nejjednodušším je textový formát s oddělovači