Apache Spark / Dataframe API vs. SQL
Working with data using Apache Spark is possible in several ways. If you come more from a software development background, you will likely lean towards using the Dataframe API, i.e., calling functions like select, filter, orderBy and others.
df.select(
col("hodnota").as("quantity"),
col("rok").as("year"),
col("DRUHZVIRE_txt").as("animal")
).filter(col("uzemi_txt") === lit("Olomoucký kraj"))
.filter(col("year") === lit("2018"))
.orderBy(desc("quantity"))
.show()
+--------+----+---------------+ |quantity|year| animal| +--------+----+---------------+ | 609373|2018| Drůbež| | 146772|2018| Slepice| | 92806|2018| Skot| | 85838|2018| Prasata| | 39619|2018| Krávy| | 9936|2018| Ovce| | 5589|2018|Prasnice chovné| | 1829|2018| Koně| | 1599|2018| Kozy| +--------+----+---------------+
For those who, on the other hand, prefer thinking in “standard” SQL, the Spark SQL module is intended.
df.createOrReplaceTempView("animals")
sparkSession
.sql(
"""SELECT hodnota AS quantity
| , rok AS year
| , DRUHZVIRE_txt AS animal
| FROM animals
| WHERE (uzemi_txt='Olomoucký kraj')
| AND (rok='2018')
| ORDER BY 1 DESC
|""".stripMargin
)
.show()
+--------+----+---------------+ |quantity|year| animal| +--------+----+---------------+ | 609373|2018| Drůbež| | 146772|2018| Slepice| | 92806|2018| Skot| | 85838|2018| Prasata| | 39619|2018| Krávy| | 9936|2018| Ovce| | 5589|2018|Prasnice chovné| | 1829|2018| Koně| | 1599|2018| Kozy| +--------+----+---------------+
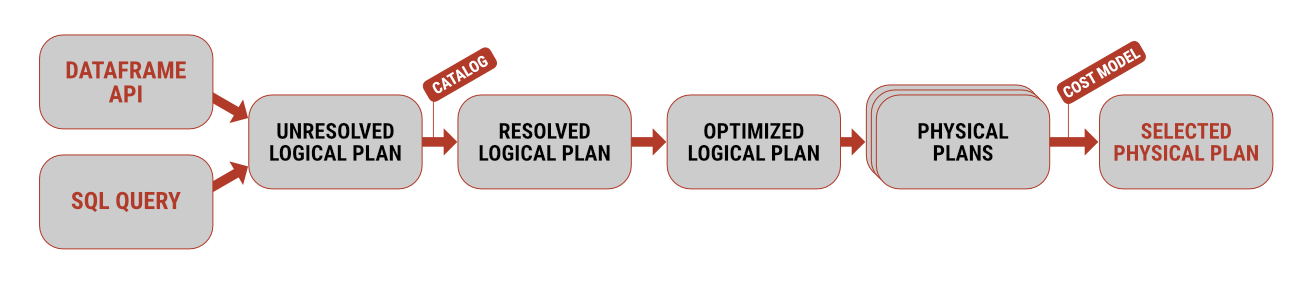
Both approaches have their pros and cons, but from a performance perspective, they are identical. In the background, for both queries, a so-called logical plan is first generated, which guarantees the formal correctness of the syntax. This is then subjected to analysis, i.e., verifying that the tables and columns used actually exist and that the data types used match the source data. Only after this step does one of the strongest aspects of Spark come into play – optimization, the creation of several physical plans (= ways to execute the commands on the specific hardware), and subsequently, the selection of the one that can process the query in the shortest possible time and with the least possible amount of resources.
The entire project with examples is available on GitHub.