Apache Spark / Wick: Type-Safe Spark API
Whether you prefer writing queries in Spark SQL or you are more used to calling functions via the Dataframe API, it’s only a matter of time before you run into a classic problem.
The volume of data grows exponentially every year, which traditional relational databases are not prepared to handle. Processing intervals are shortening, and unstructured data from multiple sources is being analyzed. This issue is addressed by technologies within the Hadoop ecosystem, such as the HDFS distributed file system, the Apache Spark computing framework, columnar data storage formats like Apache Parquet, and others.

Whether you prefer writing queries in Spark SQL or you are more used to calling functions via the Dataframe API, it’s only a matter of time before you run into a classic problem.
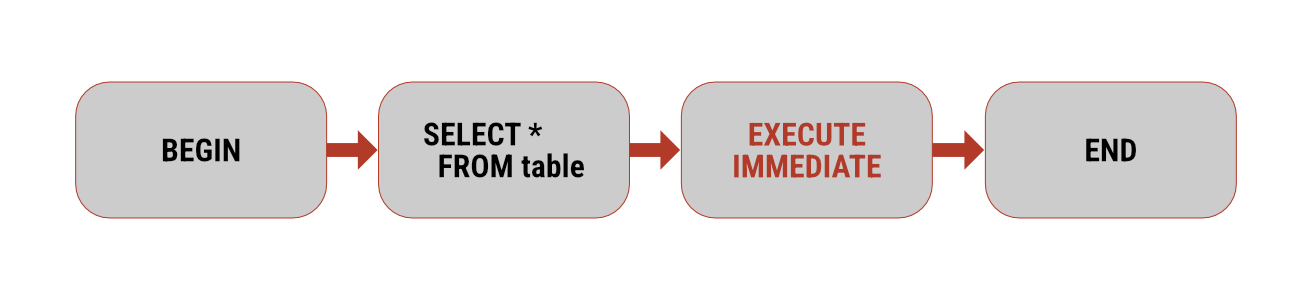
Apache Spark 4.0 introduces a significant enhancement to its SQL capabilities: experimental support for procedural language.
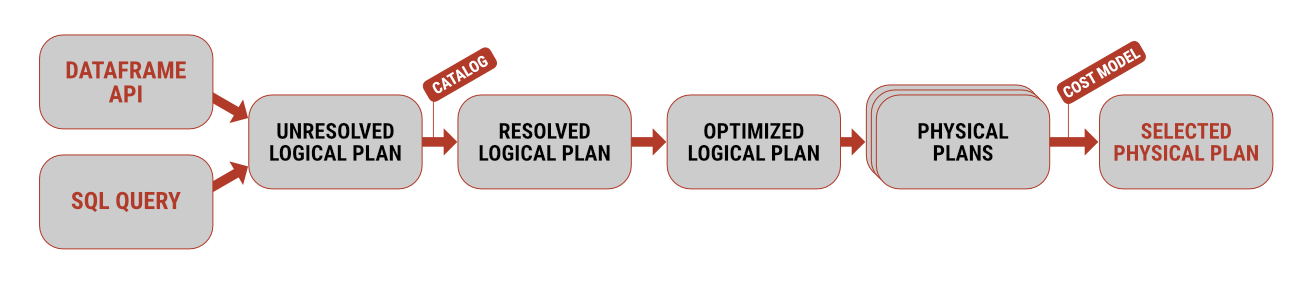
Working with data using Apache Spark is possible in several ways. If you come more from a software development background, you will likely lean towards using the Dataframe API

Apache Spark, as one of the main representatives of distributed computing systems, supports several formats for reading and writing. Probably the simplest of these is the delimited text format
Recent comments
-

TechSavvySam
You've explained this better than anyone else I've…
Add a comment...